1.文件打开的四种方式:
# f = open(r'C:\Users\fengzi\Desktop\a.txt','r',encoding='utf-8')
如果直接这样打开文件,会因为无法判断是文件路径中的\还是转义字符中的\,而产生冲突,导致错误
所以文件打开时,有以下的几种方式:
f = open('文件的绝对路径 ','文件的执行方式(r,w,a)',encoding='文件的编码方式')
#用什么字符编码写的,你就需要用什么字符编码读
# f = open('C:\\Users\\fengzi\\Desktop\\a.txt','r',encoding='utf-8')
# f = open('C:/Users/fengzi/Desktop/a.txt','r',encoding='utf-8')
# f = open(r'C:\Users\fengzi\Desktop\a.txt','r',encoding='utf-8')
如果使用以上的这三种方式打开文件,则在对文件操作之后,必须手动关闭,即:
必须在最后加 f.close()
# with open(r'C:\Users\fengzi\Desktop\a.txt','rb') as f:
#如果是用with关键字打开文件,则不需要手动关闭
2.文件处理的几种简单函数(了解)
#应用程序是不能直接操作硬件的,应用程序需要通过os操作硬件
# f = open(r'C:\Users\fengzi\Desktop\a.txt','a',encoding='utf-8')
# f.flush()#保存
# res = f.readable()#判断文件是否可读
# res = f.writable()#判断文件是否可写
# print(res)
# f.close()
3.文件处理的读、写方法
#读方法
#8位1字节,1024bytes(字节)是1kb,
# f = open(r'C:\Users\fengzi\Desktop\a.txt','r',encoding='utf-8')
# data = f.read(4)#4是字符不是字节
# print(data)
# f.close()
# f = open(r'C:\Users\fengzi\Desktop\a.txt','r',encoding='utf-8')
# f.read(4)#4是字符不是字节
# data = f.read()#读取光标右边所有字符
# print(data)
# f.close()
# f = open(r'C:\Users\fengzi\Desktop\a.txt','r',encoding='utf-8')
# data = f.readline()#readline按行读取
# print(data)
# f.close()
#写方法(覆盖)
# f = open(r'C:\Users\fengzi\Desktop\a.txt','w',encoding='utf-8')
# f.write('哈哈哈,哈哈哈')#write方法覆盖原有内容
# f.writelines(('你','好','美','女','11'))#把列表或者元组拼接成一行字符串写入文件中
# f.close()
#写方法(不覆盖)
# f = open(r'C:\Users\fengzi\Desktop\a.txt','a',encoding='utf-8')
# f.write('哈哈哈,哈哈哈')
# f.writelines(['s','b'])
# # f.close()
4.bytes类型操作文件
# a = '你好'.encode('utf-8')#转码成utf-8类型的文件
# print(a.decode('utf-8'))#解码
# f = open(r'C:\Users\fengzi\Desktop\a.txt','rb')
bytes本身就是一种文件编码的类型,所以打开时,不需要指定文件编码类型。
rb:r表示读,b表示是bytes类型文件
# print(f.read().decode('utf-8'))
# f.close()
#
# b'你好'不可以转化成bytes,b'abc'可以把abc字符串转化成bytes
# f = open(r'C:\Users\fengzi\Desktop\a.txt','wb')
# f.write(b'123')
# f.close()
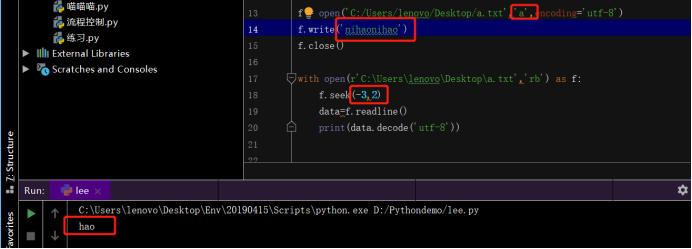
5.光标移动
seek()函数,控制光标移动,包含三种模式(0,1,2)
#0模式可以用在bytes类型和字符类型,1,2模式只能用在bytes类型下
#常用汉字在utf-8当中占3个字节,生僻字占的更多
# with open(r'C:\Users\fengzi\Desktop\a.txt','rb') as f:
# f.seek(0)#把光标移动到开头
# data = f.read()
# print(data)
# f.read(1)
# f.seek(5,1)#1代表相对位置
# print(f.read().decode('utf-8'))
# f.seek(-4,2)#2代表把光标移动到末尾
# data = f.read()
# print(data)
seek(光标移动的方向和移动几位,模式类型)
正数表示向右移动几位,例如seek(5,1)表示从当前位置向右移动5位
负数表示向左移动几位,例如seek(-5,2)表示将光标从文件末尾向左移动5位
转义字符虽然不会在文本中显示,但是依旧占用字符,所以光标移动的时候,一定要考虑到:
例如:换行符!!
有换行符时:
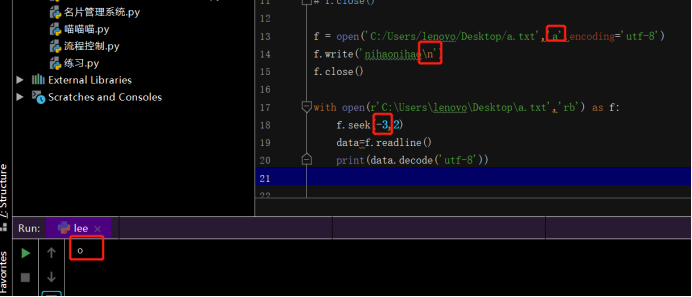
没有换行符时: